
![]()
Mr Louis-Philippe Sondeck, doctorant chez Orange Labs, qui effectue actuellement sa thèse sous la direction du Professeur Maryline Laurent et co-encadré par Mr Vincent Frey, est intervenu lors d'un atelier interne de la Chaire pour présenter les résultats de ses travaux de recherche. Ces derniers permettent de mesurer le degré d'anonymat d’une donnée figurant dans une base de données anonymisées. Pour ce faire, Louis-Philippe Sondeck propose une nouvelle métrique appelée la Discrimination Rate (DR) qui lui permet de soutenir la thèse suivante contraire aux idées reçues : l'anonymisation d'une base de données n'aboutit pas nécessairement à une moins bonne utilité des informations qui y figurent.
 Cette approche se base sur la théorie de l'information et utilise l'entropie[1] pour mesurer la perte d'information induite par l'opération d'anonymisation. Elle permet ainsi de protéger la vie privée des personnes concernées par les données tout en garantissant l’utilité de ces mêmes données pour le développement et l’amélioration des services.
Cette approche se base sur la théorie de l'information et utilise l'entropie[1] pour mesurer la perte d'information induite par l'opération d'anonymisation. Elle permet ainsi de protéger la vie privée des personnes concernées par les données tout en garantissant l’utilité de ces mêmes données pour le développement et l’amélioration des services.
Les données personnelles représentent des enjeux économiques forts à la fois pour les entreprises et les citoyens. Elles sont utilisées dans presque tous les secteurs d’activité, entre autre pour analyser la consommation, réduire les coûts de transactions, accroître la rentabilité des publicités.
Le problème que tentent de résoudre les recherches portant sur l’anonymisation de bases de données réside dans l’impossibilité de ré-identifier une personne ou d’inférer des informations supplémentaires sur un individu ou un ensemble d’individus. Souvenons-nous du cas médiatisé en 2006 de l’entreprise American On Line (AOL) qui a publié 20 millions de requêtes web sous forme soit disant anonymisée et qui a abouti finalement, par recoupement d’informations, à la ré-identification de Thelma Arnold, une veuve de 62 ans vivant à Lilburn aux Etats-Unis.
En Europe, le Règlement général sur la protection des données (RGPD) précise qu’il ne s’applique pas au traitement d’informations anonymes, les informations anonymes étant définies comme « les informations ne concernant pas une personne physique identifiée ou identifiable. » Pour autant, le texte qui se veut technologiquement neutre ne préconise aucune méthode d’anonymisation et ne précise pas le niveau d’anonymisation à atteindre.
La métrique DR définie dans la thèse quantifie de façon fine le niveau d’anonymisation d’une base de données en calculant une valeur entre 0 et 1. Elle permet de mesurer le pouvoir discriminant associé à chaque type d’attribut figurant dans une base de données, voire aux valeurs spécifiques des attributs dans cette base de données, afin d’évaluer à la fois le degré de ré-identification et la capacité d’inférer de l’information.
Ainsi il est possible d’envisager d’anonymiser plus finement une base de données qu’avec les méthodes classiques actuelles. En effet, grâce à la précision du DR, il est possible de cibler l’attribut sur lequel il convient de porter l’anonymisation prioritairement et ainsi limiter la dégradation des données pour en conserver une meilleure utilité.
Afin d’illustrer simplement le DR, prenons l’exemple de la table anonymisée 2 qui représente une implémentation spécifique du modèle d’anonymisation k-anonymat (une 3-anonymisation plus précisément) appliquée à la table brute 1.
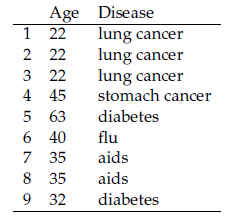
Table 1
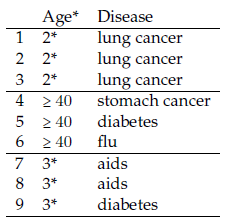
Table 2
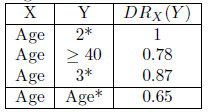
Table 3
Pour évaluer le niveau d’anonymisation, nous évaluons la capacité de l’attribut Age* à discriminer les valeurs de Age, le résultat étant présenté dans la Table 3. Nous observons que l’attribut Age* permet de discriminer les valeurs de l’attribut Age avec un DR global de 0.65. L’évaluation est aussi faite en fonction de valeurs particulières et nous constatons, par exemple, que la valeur 2* discrimine parfaitement les valeurs de Age (DR = 1). En effet, dans la table anonymisée 2, les personnes âgées d’une vingtaine d’années ont 22 ans. Nous calculons ainsi la capacité d’un attaquant de partir de l’attribut anonymisé Age* pour remonter à l’attribut non anonymisé Age.
Pour évaluer l’utilité des données, nous évaluons la capacité de Age* à discriminer une maladie particulière, le résultat étant présenté dans la Table 4. Nous observons que l’attribut Age* permet de discriminer les valeurs de l’attribut Disease avec un DR global de 0.52. Aussi, nous constatons que la valeur 2* discrimine parfaitement les valeurs de l’attribut Disease (DR = 1) car tous les sujets qui ont une vingtaine d’années sont atteints par le cancer du poumon, ce qui n’est pas le cas pour les autres valeurs de la variable Age*. Il sera donc possible d’administrer le traitement contre le cancer du poumon juste sur la base de l’âge du sujet, ce qui répond à un besoin en termes d’utilité.

Table 4
_____
Nous invitons les lecteurs intéressés à lire la thèse de Mr Louis-Philippe Sondeck ou à en lire un résumé plus complet.
Ces travaux ont fait l’objet de deux publications :
L.P. Sondeck, M. Laurent, V. Frey, "Discrimination Rate: An attribute-Centric Metric to Measure Privacy", Annals of Telecommunications, DOI: 10.1007/s12243-017-0581-8, 2017
L.P. Sondeck, M. Laurent, V. Frey, “The Semantic Discrimination Rate metric for Privacy Measurements which Questions the Benefit of t-closeness over l-diversity”, 14th International Conference on Security and Cryptography, SECRYPT 2017, ISBN 978-989-758-259-2, Madrid, Spain, 24-26 July 2017.
_____
Louis-Philippe Sondeck, doctorant, convention CIFRE entre Télécom SudParis et Orange Labs
_____
[1] Quantité moyenne d'information attribuable à un message constitué par un ensemble de signaux, représentant le degré d'incertitude où l'on est de l'apparition de chaque signal.